GdiSDK探幽3-与GDIM交互
发布时间:2026-05-09
写在前面
在上一篇 中我们已经完成了『读取数据、清洗数据、补充字段』,一路畅通无阻。这时候大家就会很自然地想到下一步:能不能把结果稳定、规范地写回GDIM,直接进入项目数据资产体系?
答案是:当然可以,而且非常简单。这一篇我们就通过一个常见场景,带你看看 GdiSDK 如何把『本地处理』自然升级为『与 GDIM 联动』的完整流程,让数据从『能算』变得『可交付、可沉淀、可复用』。
仅需一条Pipeline
很多人在做数据处理时都遇到过这个痛点:脚本写完了,结果也出来了,但入库还要再写一套接口逻辑、字段映射逻辑、权限与登录逻辑等。流程一长,维护成本就上来了。
在 GdiSDK 里,这件事可以被大幅简化。我们只需要在原有 Pipeline 的基础上增加 GdimTableWriter 模块,并配置好 token、proj_id、目标表名和字段映射,整条链路就能自动打通。换句话说,我们写的不是一次性脚本,而是一个可持续复用的数据应用流程。
举个例子
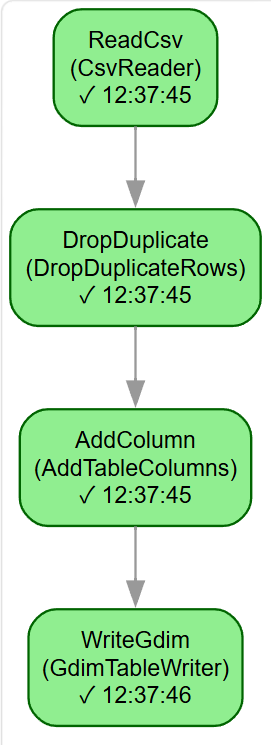
以『数据写入钻孔一览表』为例,代码流程非常直观:
- 用
CsvReader读取地层表 CSV。 - 用
DropDuplicateRows按钻孔编号去重,保证入库数据更干净。 - 用
AddTableColumns生成业务字段layer_name,把『地层编号 + 岩性名称』直接拼装成可读名称。 - 用
pipeline.update_gdim_state()来『登陆』GDIM。 - 用
GdimTableWriter指定钻孔一览表和字段映射,一键写入 GDIM。
这个案例最有价值的地方在于:业务逻辑和平台对接被统一在同一个 Pipeline 中。数据读取、数据清洗、数据加工、数据入库,全流程可视、可追踪、可复用,后续换项目时只需微调参数即可复用。
下图所示为该案例的流程图:
结语
当把『数据处理 + GDIM写入』放进同一条 Pipeline 的时候,很多重复劳动其实已经消失了:不用反复拼接接口、不用手写繁琐转换、不用担心流程难以复用。
这正是 GdiSDK 的价值所在:用更少的代码,完成更完整的业务闭环;用模块化方式,把个人经验沉淀为团队可复用的数字资产。这不仅是『能跑通』,更是『跑得稳、跑得快、跑得久』。
如何在GDIM中配置数据对接应用请参考:

可扫码查看本文对应的源代码及更多案例代码:

扫码访问GdiSDK开发文档:

扫码观看GdiSDK官方入门课程(第一期):

相关主题
GdiSDK探幽2-玩转地层表数据(https://mp.weixin.qq.com/s/FCJ8MRSZ0ppqFTlQOOsyWA)
完全免费!GdiSDK 0.3发布:让地学与环境工程师用AI构建自己的专业软件(https://mp.weixin.qq.com/s/xQmbneKpAwcwp6PYHv3mOQ)
